Beyond the Wrapper: Building Production-Grade Local RAG Pipelines in Modern Full-Stack Architectures
Move past basic AI wrappers. Learn how to architect high-performance, local RAG pipelines for enterprise apps using Next.js, local LLMs, and vector storage.
The initial hype of AI integration was dominated by the "API Wrapper"—a simple Next.js API route that forwarded a prompt to OpenAI, waited for a response, and streamed it back to a standard chat UI. It worked fine for simple MVPs.
But as we build high-velocity digital products for enterprise clients, the landscape has fundamentally shifted. Relying entirely on cloud-based LLM APIs brings massive challenges: unpredictable latency, spiraling API costs at scale, and critical data privacy concerns.
If you are handling proprietary business data, financial records, or internal company knowledge bases, sending raw data to external third-party endpoints is often a non-starter.
The solution? Moving the intelligence closer to the data.
By architecting local, self-improving RAG (Retrieval-Augmented Generation) pipelines that combine self-hosted/local LLMs (like Llama 3 or Mistral) with localized vector storage, we can build ultra-secure, hyper-contextual applications that scale without linear cost increases.
Here is a breakdown of how to architect a production-ready, local RAG pipeline using a modern full-stack ecosystem.
The Architectural Blueprint
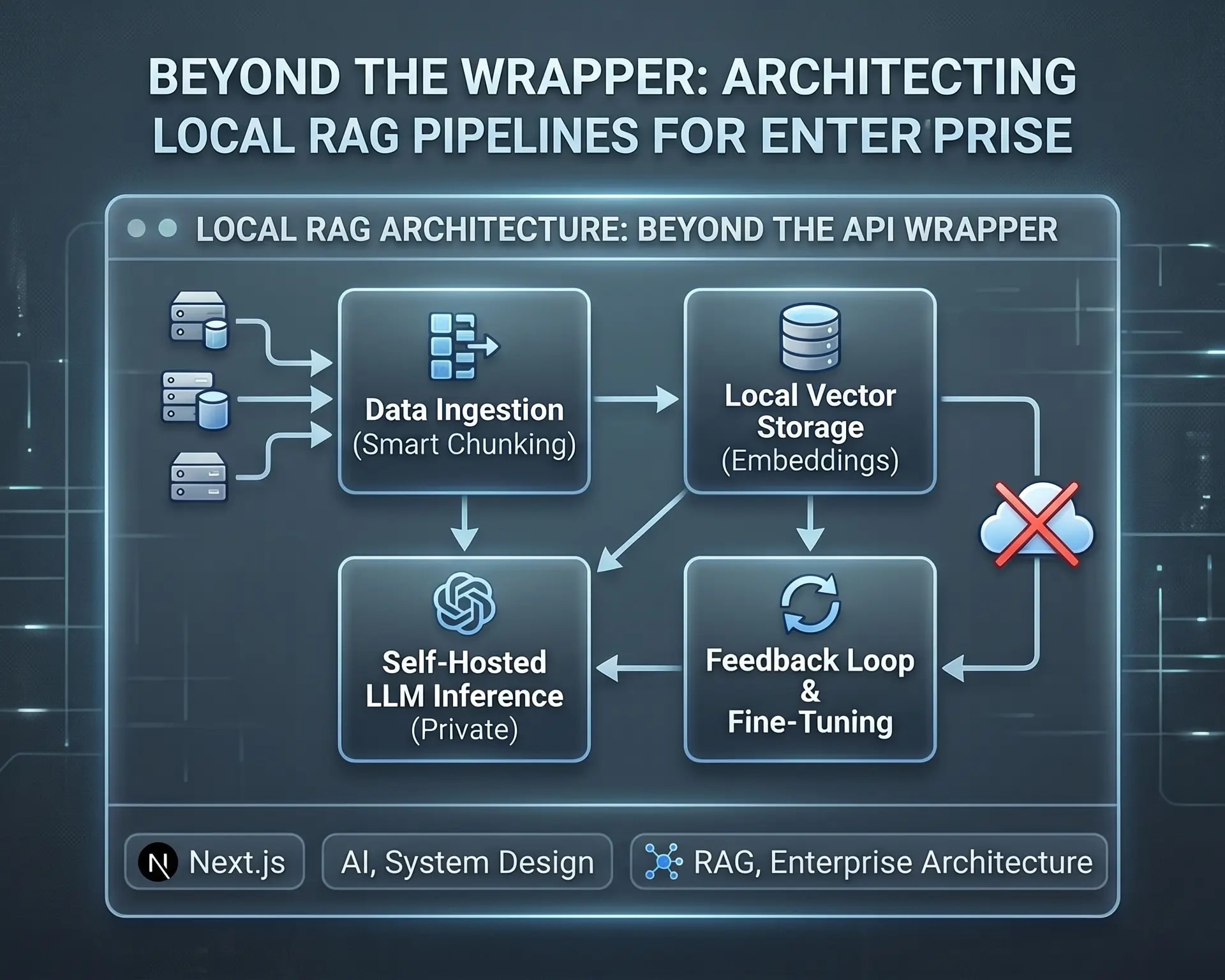
A resilient, production-grade local RAG architecture consists of four distinct layers:
[ Data Ingestion / Processing ] ──> [ Vector Storage (Local/Edge) ]
│
[ Local LLM / Fine-Tuning Engine ] <─── [ Contextual Retrieval ]
1. The Ingestion Engine (The Foundation)
You can’t just dump massive PDF manuals or unstructured databases into an LLM and expect high-quality results. Your ingestion pipeline needs to be smart.
- Smart Chunking: Instead of naive character-count splitting, use semantic chunking. Break data down by document structure (headers, markdown sections, or logical paragraphs) to preserve the context.
- Local Embedding Generation: Instead of calling external embedding endpoints, use localized libraries like
Transformers.jsor run a localOllamainstance utilizingbge-large-enorall-MiniLM-L6-v2to vectorize text chunks on your own hardware infrastructure.
2. High-Performance Local Vector Storage
For a Next.js or Node.js/NestJS microservices architecture, you need a vector database that offers lightning-fast semantic search with minimal overhead.
- On-Prem/Self-Hosted: Deploying Milvus, Qdrant, or using
pgvectorwithin an existing multi-tenant PostgreSQL setup keeps the data infrastructure consolidated. - The Retrieval Strategy: Move away from basic vector similarity searches. To achieve enterprise-grade accuracy, implement Hybrid Search (combining keyword-based BM25 search with dense vector embeddings) and apply a Reranking step (using a local cross-encoder model) to ensure the absolute most relevant context is fed to the LLM.
3. Execution via Local Inference Engines
Instead of relying on remote endpoints, the orchestration layer queries a self-hosted LLM execution environment.
- For development and local specialized setups,
OllamaorvLLMprovides highly optimized inference loops utilizing local consumer hardware (like dedicated RTX GPUs). - By keeping the LLM local, your API middleware (e.g., a NestJS service or Next.js Edge Runtime connecting to a secure internal node) can stream responses securely via WebSockets or Server-Sent Events (SSE) at 60+ tokens per second with zero external bandwidth dependency.
4. The Self-Improving Feedback Loop
The true differentiator of an elite AI product is its capability to self-correct.
By logging user interactions, tracking thumbs-up/thumbs-down signals, and auditing cases where the model flags "insufficient context," you can automatically curate a premium evaluation dataset. This clean dataset can then be fed back into an asynchronous automated pipeline to fine-tune the base weights of your local model, making it smarter over time based on actual production usage.
Why This Matters for Modern Digital Products
When building premium applications or scalable SaaS platforms, this architectural shift offers three major competitive advantages:
- Absolute Data Sovereignty: Corporate data never leaves your secure infrastructure. Compliance with strict data localization and privacy standards comes out of the box.
- Predictable Infrastructure Costs: You replace volatile, volume-based API token billing with predictable, flat-rate infrastructure scaling (e.g., dedicated AWS EC2 instances or local private servers).
- Sub-Second Latency: Eliminating external network round-trips to public LLM endpoints allows for high-velocity user interfaces and immediate data rendering.
Moving Forward
The era of basic API integration is evolving into an era of deep AI systems engineering. As full-stack developers, our job isn't just to write clean UI code or map data schemas—it’s to design the data flows and computing infrastructure that make applications fast, private, and highly autonomous.
Are you still relying purely on cloud wrappers, or are you exploring local, self-hosted AI execution? Let's connect and discuss building the next generation of high-velocity, intelligent systems.